Demystifying Poisson Regression: Simulations and Real-Life Examples
Poisson Regression is an essential statistical technique that helps us model count data or discrete events occurring over time or space. In this article, we will explore the intricacies of Poisson Regression by breaking down its core concepts, understanding its assumptions, and demonstrating its practical applications through simulations and real-life examples.

Table of contents
- Understanding Count Data and Poisson Regression
- Assumptions of Poisson Regression
- Implementing Poisson Regression with Simulations
- Real-Life Examples of Poisson Regression
- Limitations and Extensions
- Conclusion
- Understanding Count Data and Poisson Regression
Introduction
Count data refers to non-negative integer values that represent the number of occurrences of a specific event. Examples of count data include the number of customers visiting a store, the number of goals scored in a soccer match, or the number of vehicles passing through a toll booth.
Poisson Regression is a type of generalized linear model (GLM) that can be used to analyze count data. It models the relationship between a count-dependent variable and one or more independent variables by estimating a Poisson distribution parameter known as the “rate” or “intensity” (λ). The rate parameter is directly linked to the expected number of events in a given interval.
Assumptions of Poisson Regression
Poisson Regression relies on several assumptions:
Non-negative integer count data: The dependent variable should be count data, with values being non-negative integers.
Independence: The events being counted should be independent, meaning the occurrence of one event does not influence the probability of another event occurring.
Mean and variance equality: The mean and variance of the count data should be approximately equal, which is a property of the Poisson distribution.
Linearity: The relationship between the natural logarithm of the rate parameter (λ) and the independent variables should be linear.
Implementing Poisson Regression with Simulations
To better understand Poisson Regression, let’s simulate a dataset and apply the technique step by step:
Generating a dataset: We’ll create a dataset with 1,000 observations, simulating the number of customers visiting a store based on three factors: advertising budget, store size, and the day of the week.
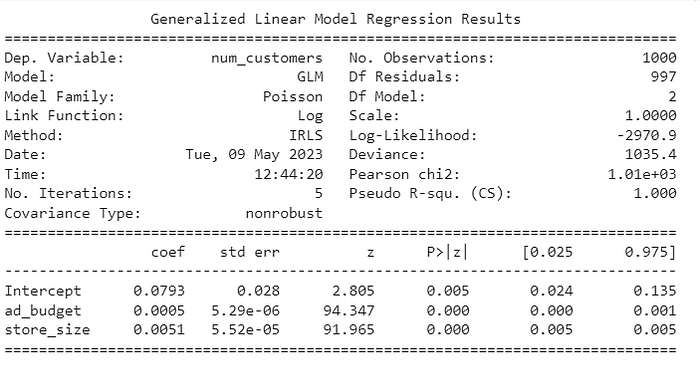
Creating a Poisson Regression model: We’ll use a statistical software package (e.g., R or Python) to fit a Poisson Regression model to our dataset, with the number of customers as the dependent variable and the three factors as independent variables.
Interpreting the model coefficients: The coefficients obtained from the model will tell us how each factor influences the expected number of customers in the store. For example, a positive coefficient for the advertising budget indicates that an increase in budget leads to more customers.
Assessing model fit: We’ll use goodness-of-fit statistics (e.g., deviance, Akaike Information Criterion) to determine how well our model fits the data.
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
# Seed for reproducibility
np.random.seed(103)
# Step 1: Generating the dataset
n = 1000
ad_budget = np.random.uniform(1000, 5000, n)
store_size = np.random.uniform(100, 500, n)
day_of_week = np.random.randint(1, 8, n)
# True parameters for the simulation
true_params = np.array([0.1, 0.0005, 0.005])
# Linear predictor (log scale)
log_lambda = true_params[0] + true_params[1] * ad_budget + true_params[2] * store_size
# Rate parameter (exponentiate to get the expected number of customers)
lambda_ = np.exp(log_lambda)
# Generate the observed number of customers using a Poisson distribution
num_customers = np.random.poisson(lambda_)
# Create a DataFrame to store the simulated data
data = pd.DataFrame({'num_customers': num_customers,
'ad_budget': ad_budget,
'store_size': store_size,
'day_of_week': day_of_week})
# Step 2: Creating the Poisson Regression model
model = smf.glm('num_customers ~ ad_budget + store_size + C(day_of_week)', data=data, family=sm.families.Poisson())
# Step 3: Fitting the model
results = model.fit()
# Step 4: Displaying the model coefficients and goodness-of-fit statistics
print(results.summary())
# Optional: Assessing goodness-of-fit using deviance and AIC
print(f"Deviance: {results.deviance}")
print(f"AIC: {results.aic}")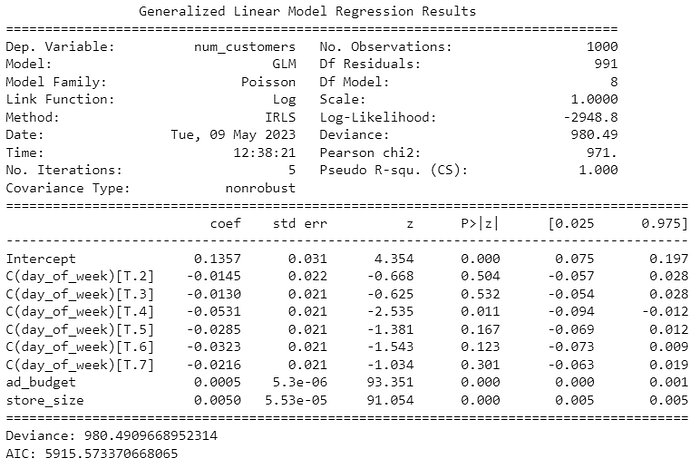
Real-Life Examples of Poisson Regression
Poisson Regression has been widely applied in various domains to analyze count data:
Public health: Researchers use Poisson Regression to model the number of disease incidences or hospital admissions based on factors like age, gender, and environmental conditions.
Finance: Poisson Regression is used to predict the number of insurance claims or loan defaults based on clients’ demographic and financial information.
Sports analytics: Analysts use Poisson Regression to model the number of goals or points scored in games to make predictions and evaluate team performance.
Traffic engineering: Engineers use Poisson Regression to model the number of vehicles passing through intersections or the number of accidents at specific locations, considering factors like road conditions, traffic volume, and weather.
Ecology: Poisson Regression is applied to study the abundance of species in relation to environmental factors, such as the relationship between the number of birds in an area and the availability of food resources or suitable habitats.
Marketing: Analysts use Poisson Regression to understand the relationship between promotional activities, product pricing, and customer purchase behavior.
Limitations and Extensions
While Poisson Regression is a powerful tool for analyzing count data, it has some limitations:
Overdispersion: When the variance of the count data is much larger than the mean, the model may not fit well, leading to overdispersion. In such cases, a Negative Binomial Regression or a Quasi-Poisson Regression can be used as an alternative.
Zero-inflation: Poisson Regression may not adequately handle datasets with an excessive number of zeros, which can lead to biased estimates. Zero-Inflated Poisson (ZIP) or Hurdle models can be employed to address this issue.
Non-linearity: Poisson Regression assumes a linear relationship between the natural logarithm of the rate parameter and the independent variables. If this assumption is violated, nonlinear models or transformation of the independent variables may be necessary.
Conclusion
Poisson Regression is a versatile and powerful statistical technique for modeling count data. It enables researchers and practitioners to better understand the relationships between the occurrence of events and various factors that may influence them. By using simulations and real-life examples, we have explored the key concepts, assumptions, and applications of Poisson Regression.
Despite its limitations, Poisson Regression remains an essential tool for analyzing count data across a wide range of disciplines. By understanding its strengths and weaknesses and applying appropriate extensions when necessary, researchers and practitioners can effectively harness the power of Poisson Regression to address complex problems and make informed decisions.
Bonus
To perform variable selection in Python for a Poisson regression model, we can use the stepwise selection approach, which iteratively adds and removes variables based on their significance. We’ll use the statsmodels library for this task as well.
Here’s a stepwise selection function and an example of how to use it with our simulated dataset:
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
def stepwise_selection(data, response, initial_candidates, alpha_enter=0.05, alpha_remove=0.1):
remaining_candidates = set(initial_candidates)
selected_candidates = []
current_score, best_new_score = float('inf'), float('inf')
while remaining_candidates and current_score == best_new_score:
scores_with_candidates = []
for candidate in remaining_candidates:
formula = f"{response} ~ {' + '.join(selected_candidates + [candidate])}"
model = smf.glm(formula, data=data, family=sm.families.Poisson())
results = model.fit()
score = results.aic
scores_with_candidates.append((score, candidate))
scores_with_candidates.sort(reverse=True)
best_new_score, best_candidate = scores_with_candidates.pop()
if current_score > best_new_score:
remaining_candidates.remove(best_candidate)
selected_candidates.append(best_candidate)
current_score = best_new_score
model = smf.glm(f"{response} ~ {' + '.join(selected_candidates)}", data=data, family=sm.families.Poisson())
results = model.fit()
# Removing insignificant variables
pvalues = results.pvalues
for variable, pvalue in pvalues.items():
if pvalue > alpha_remove and variable != 'Intercept':
selected_candidates.remove(variable)
# Refitting the model with the remaining variables
final_model = smf.glm(f"{response} ~ {' + '.join(selected_candidates)}", data=data, family=sm.families.Poisson())
final_results = final_model.fit()
return final_results
# True parameters for the simulation
true_params = np.array([0.1, 0.0005, 0.005])
# Linear predictor (log scale)
log_lambda = true_params[0] + true_params[1] * ad_budget + true_params[2] * store_size
# Rate parameter (exponentiate to get the expected number of customers)
lambda_ = np.exp(log_lambda)
# Generate the observed number of customers using a Poisson distribution
num_customers = np.random.poisson(lambda_)
# Create a DataFrame to store the simulated data
data = pd.DataFrame({'num_customers': num_customers,
'ad_budget': ad_budget,
'store_size': store_size,
'day_of_week': day_of_week})
# Perform stepwise variable selection
initial_candidates = ['ad_budget', 'store_size', 'C(day_of_week)']
response = 'num_customers'
final_results = stepwise_selection(data, response, initial_candidates)
# Display the final model coefficients and goodness-of-fit statistics
print(final_results.summary())